Reed S, Akata Z, Yan X, et al. Generative adversarial text to image synthesis[J]. arXiv preprint arXiv:1605.05396, 2016.
1. Overview
1.1. Motivation
- RNNs are developed to learn discriminative text feature representations
- GANs
- two problems
- learn text feature representation that captures the important visual detailss
- features to synthesize a compelling image
In this paper, it translated visual concepts from character to pixels
- introduce manifold interpolation regularizer
1.2. Contribution
- first end-to-end text-to-image based on GAN
- zero-shot text-to-image synthesis
1.3. Related Work
- Multimodal Learning
- audio-video
- Boltzmann machine
- DeConv
- recurrent convolutional encoder-decoder
- image caption
1.4. Joint Embedding

- Δ. 0-1 loss
- v_n. images
- t_n. corresponding text description
- y_n. class labels
- f_v and f_t are parametrized by

- φ. text encoder
- Φ. image encoder
- T(y). text description of class y
- V(y). image description of class y
2. Methods

2.1. Architecture
2.1.1. G
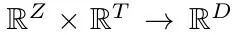
- Z. dimension of noise from N(0, 1)
- T. dimension of text embedding, encoded by text encoder φ
- D. dimension of image

- φ(t)-FC(128)-leakyReLU-concat with z
2.1.2. D

2.2. Matching-aware Discriminator (GAN-CLS)
- real + right text
- real + wrong text
- fake + right text

2.3. Learning with Manifold Interpolation (GAN-INT)

- generate a large amount of additional text embedding by interpolation between embeddings of training set captions
- found β=0.5 works well
2.4. Inverting the Generator for Style Transfer
- noise sample z should capture style factors such as background color and pose
- transfer style of a query image onto the content of a particular text description

- S. trained style encoder network
3. Experiments
3.1. Details
- pre-train char-CNN-RNN (text encoder) to increase the speed of training, produce 1024 dimension vector and project to 128 dimension
- image size 64 x 64 x 3
- LR 0.0002, Adam with 0.5 momentum
- minibatch size 64
3.2. Quantitative Results

3.3. Disentangling Style and Content
- content. visual attributes (shape, size, color of birds)
style. background color, pose oriation
text embedding mainly covers content information and typically nothing about style
- GAN must learn to use noise z for style variation
3.4. Pose and Background Style Transfer

3.5. Sentence Interpolation
